最近在总结自己的一些理论知识,发现还是有很多地方不够理解,总结到基础算法时发现很多东西都忘了,所以写下这篇博客,当是笔记吧,知识都是东拼西凑加上自己的理解写的!
排序算法
冒泡排序
概述
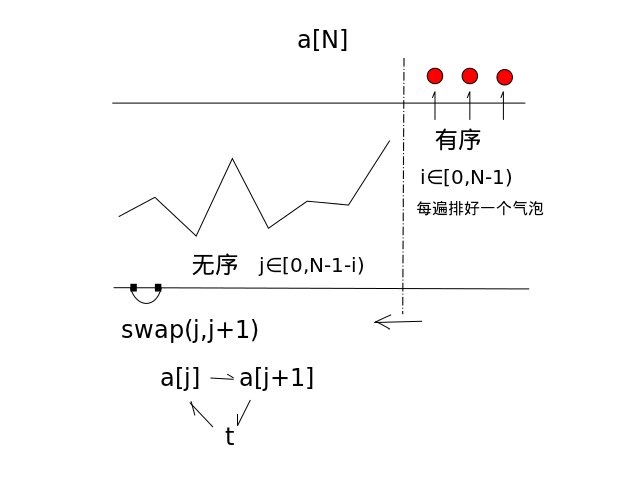
冒泡排序通过重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来,直到没有再需要交换的元素为止(对 n 个项目需要 O(n2) 的比较次数)。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
实现思路
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
性能分析
- 最差时间复杂度:O(n2)
- 最优时间复杂度:O(n)
- 平均时间复杂度:O(n2)
- 空间复杂度:总共 O(n),需要辅助空间 O(1)
Java 实现
1 | public static int[] sort(int[] numbers) { |
简单选择排序
概述
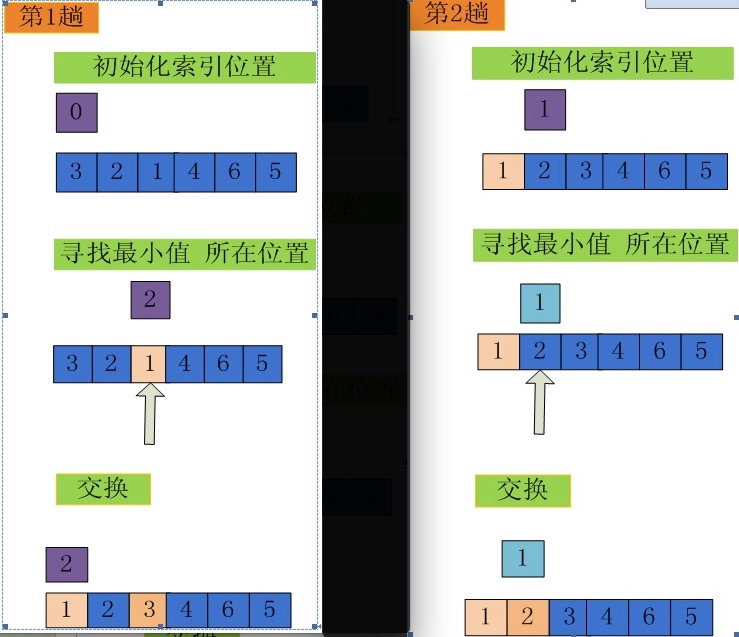
每趟从待排序的记录中选出最小的元素记录,顺序放在已排序的记录序列末尾,直到全部排序结束为止。
实现思路
- 每一轮初始化一个索引位置,索引位置逐轮增加。
- 每一轮有一个最小元素的位置,找出索引位置后面的元素的最小值,并且和索引位置交换。
- 开始下一轮,直到没有元素比较。
性能分析
- 在简单选择排序过程中,所需移动记录的次数比较少。最好情况下,即待排序记录初始状态就已经是正序排列了,则不需要移动记录。
- 最坏情况下,即待排序记录初始状态是按第一条记录最大,之后的记录从小到大顺序排列,则需要移动记录的次数最多为 3(n - 1)。
- 简单选择排序过程中需要进行的比较次数与初始状态下待排序的记录序列的排列情况无关。
- 当 i = 1 时,需进行 n - 1 次比较;当 i = 2 时,需进行 n - 2 次比较;依次类推,共需要进行的比较次数是 (n - 1) + (n - 2) + … + 2 + 1 = n(n - 1) / 2,即进行比较操作的时间复杂度为 O(n2),进行移动操作的时间复杂度为O(n)。
- 简单选择排序是不稳定排序。
Java 实现
1 | public static int[] sort(int[] numbers) { |
直接插入排序
概述
将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,是稳定的排序方法。
把待排序的纪录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的纪录插入完为止,得到一个新的有序序列。
实现思路
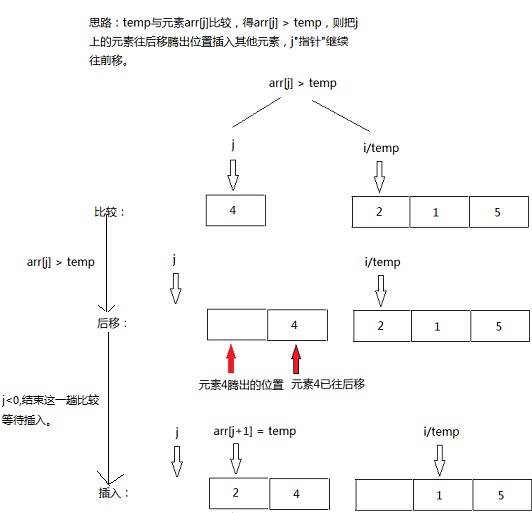
- 从第二个元素开始遍历,每一轮有一个要插入的值。
- 将要插入的值和已经排好序的数组逐一比较,如果前者小于后者中的某个元素,则该元素向后移动一位,这里会留一个空白位置。
- 然后在空白位置插入之前保存的插入值,这样新的有序数组就排好了,每一轮新增一个元素。
性能分析
- 空间复杂度:O(1)
- 平均时间复杂度:O(n2)
- 最差时间复杂度:反序,需要移动 n * (n - 1) / 2 个元素,运行时间为 O(n2)
- 最好时间复杂度:正序,不需要移动元素,运行时间为 O(n)
Java 实现
1 | public static int[] sort(int[] numbers) { |
折半插入排序
概述
直接插入排序中要把插入元素与已有序序列元素依次进行比较,效率非常低。
折半插入排序,也叫二分插入排序,使用使用折半查找的方式寻找插入点的位置,可以减少比较的次数,但移动的次数不变,时间复杂度和空间复杂度和直接插入排序一样,在元素较多的情况下能提高查找性能。
直接插入排序是,比较一个后移一个。折半插入排序是,先找到位置(使用折半查找算法),然后一起移动。
实现思路
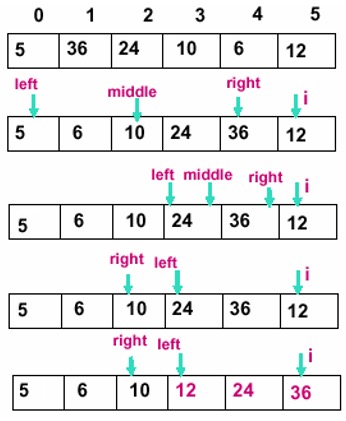
- 从第二个元素开始遍历,每一轮有一个要插入的值。
- 将要插入的值和已经排好序的数组的中间元素比较,以已经排好序的数组的中间元素为分界,确定待插元素是在已经排好序的数组的左边还是右边。
- 如果是在其左边,则以该左边序列为当前查找序列,右边也类似。
- 递归地处理新序列,直到当前查找序列的长度小于 1 时查找过程结束。
性能分析
- 时间复杂度:折半插入排序适合记录数较多的场景,与直接插入排序相比,折半插入排序在寻找插入位置上面所花的时间大大减少,但是折半插入排序在记录移动次数方面和直接插入排序是一样的,所以其时间复杂度为 O(n2)。
- 其次,折半插入排序的记录比较次数与初始序列无关。因为每趟排序折半寻找插入位置时,折半次数是一定的,折半一次就要比较一次,所以比较次数也是一定的。
- 空间复杂度:O(1)
- 折半插入排序是一种稳定的排序算法。
Java 实现
1 | public static int[] sort(int[] numbers) { |
快速排序
概述
快速排序是对冒泡排序的一种改进,又称划分交换排序。快速排序使用分治法策略来把一个序列分为两个子序列,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。快速排序是在实际中最常用的一种排序算法,速度快,效率高。就像名字一样,快速排序是最优秀的一种排序算法。
实现思路
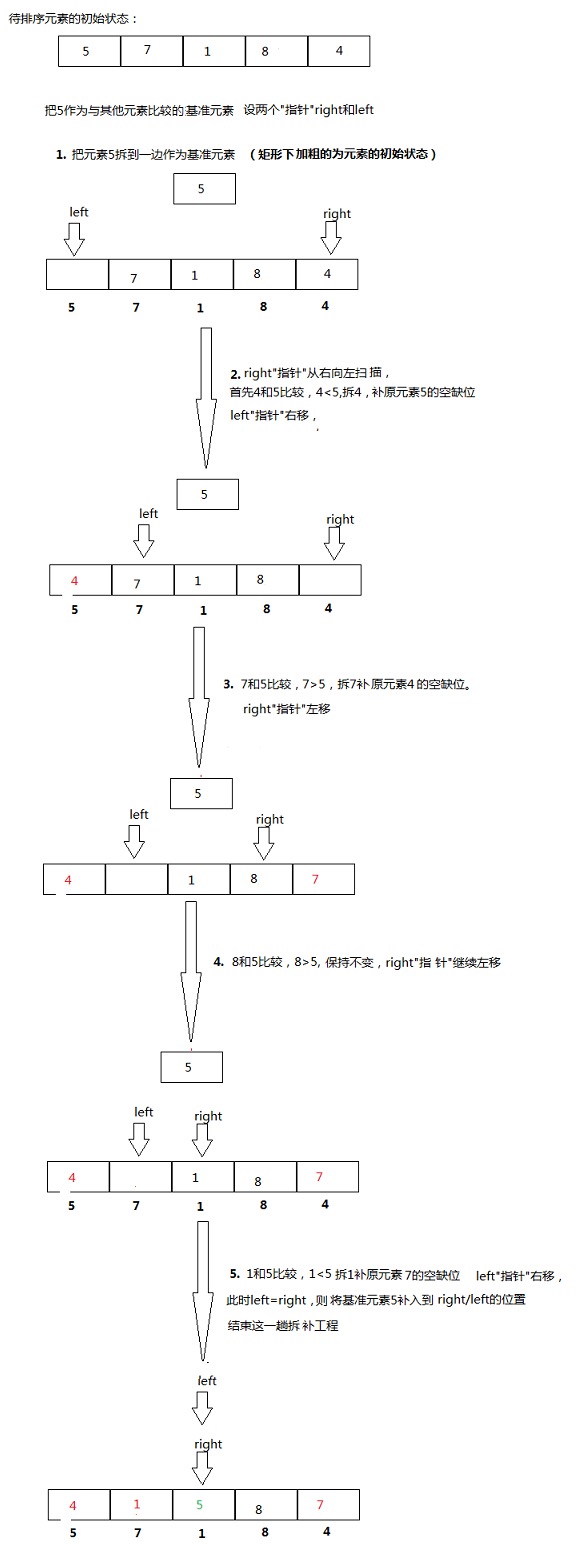
- 在待排序的元素任取一个元素作为基准(通常选第一个元素,但最好的选择方法是从待排序元素中随机选取一个作为基准),称为基准元素。
- 将待排序的元素进行分区,比基准元素大的元素放在它的右边,比其小的放在它的左边,这一步骤称为分区操作。
- 对左右两个分区重复以上步骤直到所有元素都是有序的。
- 每一次递归其实就是把选中的基准元素放在排序的中间。
性能分析
- 当分区选取的基准元素为待排序元素中的最大或最小值时,为最坏的情况,时间复杂度和直接插入排序的一样,移动次数达到最大值,此时时间复杂为 O(n2) 。
- 当分区选取的基准元素为待排序元素中的中值时,为最好的情况,时间复杂度为 O(nlog2n)。
- 快速排序的空间复杂度为 O(log2n)。
- 当待排序元素类似 [6, 1, 3, 7, 3] 且基准元素为 6 时,经过分区,形成 [1, 3, 3, 6, 7],两个 3 的相对位置发生了改变,所以快速排序是一种不稳定排序。
Java 实现
1 | public static int[] sort(int numbers[], int low, int high) { |
查找算法
顺序查找
算法描述
从表中的第一个或者是最后一个记录开始,逐个的将表中记录的关键字和给定值进行比较。若某个记录的关键字和给定值相等,则查找成功;若表中所有记录的关键字和给定值都不相等,则查找失败。
Java 实现
1 | public static boolean find(int[] numbers, int key) { |
折半查找
算法描述
又叫二分查找,它的前提条件是在一个有序的序列中。首先确定待查记录所在的区间,然后逐步的缩小范围区间直到找到或者找不到该记录为止。与数学中的二分法一样。
Java 实现
1 | public static boolean find(int[] numbers, int key) { |
斐波那契查找
算法描述
斐波那契查找是根据斐波那契序列的特点对表进行分割。假设表中记录的个数比某个斐波那契数小 1,即 n = Fn − 1,然后将给定值和表中第 Fn-1 个记录的关键字进行比较。若相等,则查找成功;若给定关键字 < 表中第 Fn-1 个记录的关键字,则继续在表中从第一个记录到第 Fn-1 − 1 个记录之间查找;若给定关键字 > 表中第 Fn-1 个记录的关键字,则继续在自 Fn-1 + 1 至 Fn − 1 的子表中查找。
斐波那契查找也是需要针对有序序列。这种查找用到了斐波那契数列的一个性质:前一个数除以相邻的后一个数,比值无限接近黄金分割。
查找的精髓在于采用最接近查找长度的斐波那契数值来确定拆分点。举个例子来讲,现有长度为 9 的数组,要对它进行拆分,对应的斐波那契数列(长度先随便取,只要最大数大于 9 即可) {1,1,2,3,5,8,13,21,34},不难发现,大于 9 且最接近 9 的斐波那契数值是 f[6] = 13,为了满足所谓的黄金分割,所以它的第一个拆分点应该就是 f[6] 的前一个值 f[5] = 8,即待查找数组的第8个数,对应到下标就是 array[7],依次类推。
Java实现
1 | public static boolean find(int[] numbers, int key) { |

