这段时间心情不是很美丽。一是觉得在现在提升不了什么能力了,二来突然思考自己是否能一直在这个行业干下去,顿时有点刚毕业时的迷茫了,这也可能是一月一次的“大姨父”。经过一段时间的思考,觉得还是应该稳扎稳打坚持下去,毕竟哥们儿现在除了这个也没其他技能了(手动流泪~~~)。于是在一个月黑风高的夜晚,突然想起来在大学时期参加过的一个软件比赛,那时候是真开心啊,毕竟仗着那个比赛在系里横着走,而且当时交了第一个喜欢的女朋友,简直让人膨胀……
扯远了,当时比赛我们弄了一个基于摄像头识别的软件,初衷是因为我爱看哈利波特,希望能通过摄像头实现用手势变魔法的功能,于是用到了 OpenCV。当时的底层算法是我的另一个队友写的,所以我对 OpenCV 基本不懂,现在突发奇想把 OpenCV 从头到尾学了一遍,这里主要把基于 OpenCV 级联分类器如何识别目标物体的过程记录下来,希望能给需要的人一点帮助。
原理简介
OpenCV 是一个跨平台的计算机视觉库,它实现了图像处理和计算机视觉方面的很多通用算法,是一个非常强大的开源库。
具体应该怎么实现物体的识别呢?我们应该知道,在计算机上看到的图像都是由一颗颗的像素点组成的,而每颗像素点的基本属性就是其颜色值,经过标准的定义,就可以用一个计算机数据结构的数据来表示一副图像。这样的标准有很多,我们经常听到的 RGB 三通道(红、绿、蓝三原色可以组成任意颜色)就是最常用的标准。OpenCV 研究的就是如何利用各种算法对像素点进行转换,达到不同的效果,而物体识别需要的过程比较繁琐,概括起来就是:
- 取样本,包括正样本(包含需要识别物体的图片)和负样本(不包含正样本的图片)。
- 对正样本进行预处理,包括图片降燥、灰度化、直方图均衡化、边缘检测、轮廓提取等。
- 提取正样本中比较明显的特征,量化为计算机数据。
- 使用机器学习算法学习样本数据,使应用程序具有对数据分类(两类或多类)的能力,这一过程称为机器训练。
- 使用训练好的模型对目标物体进行检测。
这是一般进行物体识别的步骤,其中提取样本特征这一步比较困难,因为要自己找到明显的特征需要较高深的算法,这不是像我这种入门菜鸟所能做到的。没关系,OpenCV 提供了级联分类器这个强大的东东,使用它只需要把图片缩小到足够小直接作为特征训练分类器。
准备工作
下载开发工具包
首先去 OpenCV 的官网下载 Windows 平台的开发包,这里主要是需要使用它的两个应用程序。本人还下载了对应的 Android 平台的开发包,因为我最终要在 Android 上执行。
准备正样本
对于刚性物体,比如汽车 logo,只需要一张正面的亮度足够的图片即可,因为 OpenCV 的算法可以对一张图片进行各种旋转操作,从而产生大量的样本;而非刚性物体,比如人脸,需要自行准备大量的图片,数量越多越好,至少有 1000 张图片。这里我就准备了两张 logo 图片,因为我最后只需要识别两个 logo 即可,如图:

非刚性物体的正样本图片应该是经过处理的、尺寸统一的小图片,大小控制在 20 * 20 左右,尽量让目标物体充满图片,也就是背景越少越好,而且背景色要统一。
准备负样本
负样本需要在机器训练中使用,其数量是越多越好,可以是任意的图片,只要不包含目标物体即可,这里我准备了将近 500M 的图片,真正使用时还是发现少了,建议一般至少准备 2G 的图片,可以从网上下载各种素材包,或者从一段视频中截取图片。下图是我准备的一部分负样本图片:
负样本图片的尺寸可以无限大,但是一定不能小于正样本图片的尺寸。
找到自带的程序
准备样本是一个繁琐且漫长的过程,如果想要分类器取得好的效果,样本数量一定要尽量多。样本准备就绪之后,就可以开始训练了。
找到之前下载好的开发工具包,在 /opencv/build/x64/vc14/bin/ 目录下,有一些程序可供我们进行机器训练,如下图:
我们需要其中的 opencv_createsamples.exe 和 opencv_traincascade.exe 两个程序,前者是用来创建正样本描述文件的,后者是用来进行机器训练的,当然,记得把需要的 dll 文件拷贝。
创建样本描述文件
正样本描述文件
对于正样本,需要一个后缀为 .vec 的描述文件,OpenCV 提供了一个程序 opencv_createsamples 用来生成描述文件,我们先来看看这个程序怎么使用。打开 cmd,目录切换到 /opencv/build/x64/vc14/bin/,输入 opencv_createsamples.exe,可以看到如下选项:
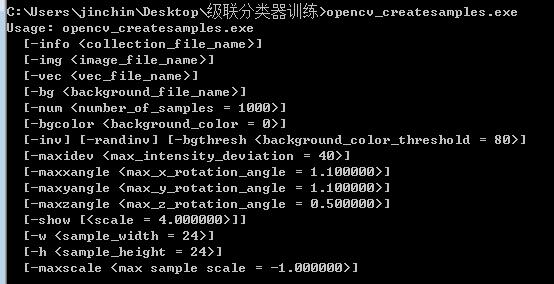
- -info:指定正样本的信息文件,后缀可以是 .txt、.dat,这个文件列出了所有正样本图片的文件名、包含待检物的数量和待检物的范围参数。比如:samples_1.jpg 1 0 0 20 20 这样,就是指某个正样本是 samples_1.jpg 的图片,图片中有 1个目标区域,区域的左上角坐标为 (0,0),区域的宽度为 20 像素,长度为 20 像素。注意样本图片和这里的参数相符,每一张图片的信息占一行,不能有空行。
- -img:指定正样本的图片文件,对于只有一张图片样本的刚性物体,应该使用这个选项来产生大量样本,通过一张图片的扭曲形变成多张图片作为样本,注意这个选项和 -info 选项只有一个能生效。
- -vec:指定生成样本描述文件的路径和文件名。
- -bg:样本背景文件,后缀可以是 .txt、.dat,如果省略,则使用 bgcolor 的值填充作为背景,内容就是图片名,每一张图片的信息占一行,不能有空行。
- -num:要创建的正样本的数量,使用 -info 生成时,不要比你准备的正样本图片数量大就行了。
- -bgcolor:创建样本时样本扭曲函数中用来决定像素是有效还是作为背景过滤的基本值,因为操作的是灰度图,所以这个值的范围是 0 ~ 255。
- -bgthresh:决定背景掩码的实际取值,范围为 bgcolor - bgthresh ~ bgcolor + bgthresh。
- -inv、-randinv:样本生成时,是否需要反向或随机反向,这个在车牌数字识别中比较常用,比如说白底黑字的车牌和蓝底白字的车牌,两者生成的样本是相反的,前者数字是黑色,后者数字是白色。
- -maxidev:一个用于生成前景(有效像素区域)灰度值的常数值,实际样本的前景灰度值会根据这个参数结合随机数产生多种不同的灰度值。
- -maxxangle、-maxyangle、-maxzangle:使用 -img 选项创建样本才会生效,是指对于样本图片的在各方向上扭曲的最大弧度,一般我们直接使用默认值,效果较好。
- -show:样本创建时,是否显示一个窗口显示每一个生成的样本图片。
- -w、-h:要创建样本图片的尺寸,这个参数要和后面训练时的一致,不然会报错。
基于以上选项,根据需求可以写一个批处理文件执行 opencv_createsamples.exe,这样不用每次设置这么多参数,我的批处理文件是这样的:
1 | opencv_createsamples.exe -img pos/pos1.png -bgcolor 255 -bgthresh 0 -vec pos1.vec -num 1200 -w 20 -h 20 |
这里我创建了 1200 个正样本,执行后在当前目录下生成了一个名为 pos1.vec 的文件,这就是我们要的正样本描述文件了。接着我把 pos1.png 换成了 pos2.png,pos1.vec 换成了 pos2.vec 来生成第二张 logo 图片的描述文件,也能正常执行。
负样本描述文件
对于负样本,不需要正样本那样麻烦,只需要创建一个后缀为 .txt 或者 .dat 的文本文件,里面的内容就是图片名,每一张图片的信息占一行,不能有空行。由于负样本较多,所以可以写一个小程序用来生成这个文件,非常简单,下图是我的负样本描述文件:

开始训练分类器
一切准备就绪后就可以开始训练分类器了,同样我们先看看程序,打开 cmd,目录切换到 /opencv/build/x64/vc14/bin/,输入 opencv_traincascade.exe,可以看到如下选项:
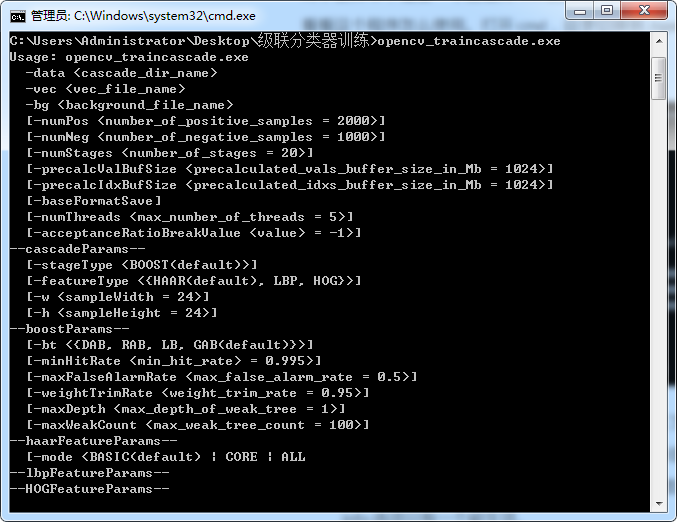
- -data:指定最后生成的分类器模型存放的目录。
- -vec:指定正样本描述文件,这个是上个步骤产生的 .vec 文件。
- -bg:指定负样本描述文件,这个是上个步骤产生的 .txt 或 .dat 文件。
- -numPos:在每一级训练中使用的正样本数量。这个参数和之前生成 .vec 时指定 -num 的有关,经过我的各种实验,发现设为 85% 最为合适,各方面都能达到平衡。
- -numNeg:在每一级训练中使用的负样本数量。这个值可以设置大于真正的负样本图像数目,因为程序会自动从负样本图像中切割出和正样本大小一致的图像块,这个参数一般设置为正样本数目的 3 倍。
- -numStages:训练级数,推荐使用 15 ~ 20,级数越高,需要的样本数量越多,当然耗时越长,检测效果越好。
- -precalcValBufSize:缓存大小,用于存储预先计算的特征值,一般使用默认值。
- -precalcIdxBufSize:缓存大小,用于存储预先计算的特征索引,一般使用默认值。
- -baseFormatSave:仅在使用 Haar 特征时有效,如果指定,级联分类器将以老格式存储。
- -numThreads:训练时开启的线程数,一般使用默认值。
- -stageType:级联算法,一般使用默认值。
- -featureType:提取的特征算法,包括 Haar、Lbp 和 Hog(Hog 好像不能用),一般使用 Lbp 特征,速度最快。
- -w、-h:训练的窗口大小,必须和之前创建样本时指定的一致,一般我们设为 20 20,这个参数太大会影响训练速度,20 20 是保证好的检测效果的同时能保证速度的一个值。
- -bt:Boosted 分类器的类型,一般使用默认值。
- -minHitRate:最小命中率,即训练目标的准确度。假设每一级训练 1000 个正样本,如果指定为 0.999,那么有一个样本会被认为是不合格的样本。一般根据正样本的数量进行设置,我的原则是让正样本逃出一个作为负样本。
- -maxFlaseAlarmRate:最大虚警(误检率),每层训练到小于这个值时结束,进入下一级训练,一般使用默认值。
- -mode:如果使用 Haar 特征,则这个选项生效,用于指定特征类型。
理解完了各个选项的含义后,我们可以写出这样一个批处理文件(之后我把 pos1.vec 换成了 pos2.vec 重新训练,从而产生两个模型文件):
1 | opencv_traincascade.exe -data data -vec pos1.vec -bg neg/neg.txt -numPos 1000 -numNeg 3000 -numStages 15 -featureType LBP -w 20 -h 20 -minHitRate 0.999 -maxFalseAlarmRate 0.5 |
执行这个批处理文件,如果顺利,会在 /data/ 目录下生成很多文件,如下图:
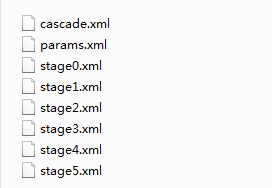
这里的 cascade.xml 就是最终训练好的模型文件,其他的都是中间文件。这里会发现一个问题,明明我指定的是训练到 15 级,为什么中间文件只到 stage5 呢?其实我在训练中抛出了这样一个警告:
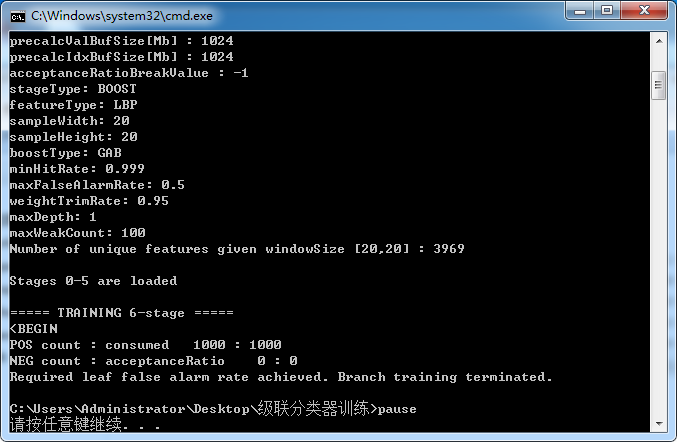
这个是告诉你已经达到了需要的虚拟率,训练已经是最好的效果,再往下并不会取的更好的效果。产生这个的原因一般就是样本数量不够,尝试增大正负样本是最好的解决办法。当然,可以通过修改参数(增大 minHitRate 或 减少 maxFlaseAlarmRate)增加训练级数,但不推荐,可能会影响检测效果。
物体识别
到了这里,麻烦的步骤可以说已经过去了,只需要使用训练好的文件即可。主要是用到 OpenCV 中的 CascadeClassifier 这个类,我以 Java 为例,将代码和注释贴出来:
1 | // 初始化级联分类器,读入 cascade.xml 文件 |
结果展示
直接把我的程序截图贴出来:


从图中可以看出来识别非常精确,当然这是经过我的各种调参达到的效果。
展望
未来会越来越好,技术会越来越好,生活会越来越好,感情会越来越好!

